Are you looking for a locally hosted open source GPT that protects your privacy while allowing to leverage the latest AI models? Then you need to download Jan. Jan is easy to install on Linux, macOS and Windows and has excellent documentation to guide that process.
Jan is a ChatGPT alternative that runs 100% offline on your desktop. The goal is to make it easy for anyone, with or without coding skills, to download and use AI models with full control and privacy. Jan operates on a truly open-source model with an Apache 2.0 license. It stores all data locally, so internet usage is optional since it can function entirely offline. Users have the flexibility to choose AI models, both local and cloud-based, without the worry of data being sold. Jan is powered by Llama.cpp, a local AI engine that offers an OpenAI-compatible API This enables you to utilize AI capabilities in various applications on your laptop or PC.
I downloaded and installed Jan on Linux Mint 22.1 using the deb file. If you are using a non-Debian based Linux like Fedora you can install the app image file. I also downloaded and installed Jan on my M3 MacBook Air. The project has excellent documentation which makes it easy to get started using Jan. Be sure to consult it.
As suggested in the documentation I downloaded and installed the Jan-nano-128K model. The project provides excellent resources which helped me to learn how to use the LLM. I decided to see if it could give me the code for a simple web app that converted Fahrenheit to Celsius using Python and Flask. The model took about fifteen seconds and then gave me the code which I copied and pasted into VSCodium and saved it as a Python file. The model suggested I install Flask and gave me the code pip3 install Flask. I saved the file as directed and then presented me with the dialogue below. The result was two files which I saved in the Python virtual environment on my computer.
The Python file:
from flask import Flask, request, render_template
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def convert_temp():
result = None
if request.method == 'POST':
fahrenheit = float(request.form['fahrenheit'])
celsius = (fahrenheit - 32) * 5/9
result = celsius
return render_template('convert.html', result=result)
if __name__ == '__main__':
app.run(debug=True)The second file was an HTML file which was stipulated in the code Jan produced.
<!DOCTYPE html>
<html>
<head>
<title>Fahrenheit to Celsius Converter</title>
</head>
<body>
<h1>Fahrenheit to Celsius Converter</h1>
<form method="post">
<label for="fahrenheit">Enter Fahrenheit:</label>
<input type="text" id="fahrenheit" name="fahrenheit" required>
<button type="submit">Convert</button>
</form>
{% if result is not none %}
<h2>Result: {{ result }}°C</h2>
{% endif %}
</body>
</html>I copied both the code snippets into VSCodium and saved them to the Python virtual environment which i created using the following command:
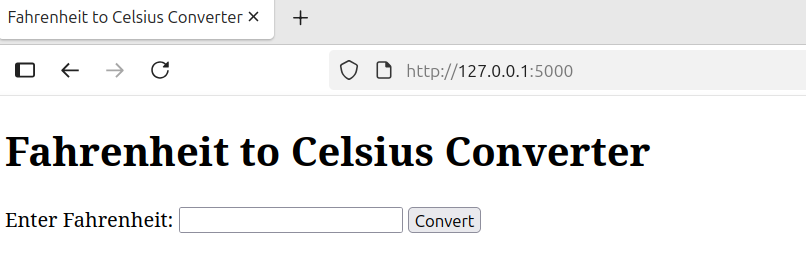
python3 -m venv temperature
I opened a terminal and gave the following command python3 temperature.py. Then I opened my browser and pointed it to https://127.0.0.1:5000 as directed and was presented with the following simple web app that I had requested the model to create.
Reading the project’s extensive documentation is crucial and I also found that the community maintains a number of useful resources including Github, Discord, X and LinkedIn. The project has a blog with a number of useful resources too.